Pseudonymization procedures
Introduction
Pseudonymization is a de-identification procedure during which personally identifiable information is replaced by a unique alias or code (pseudonym). In some situations, the researcher maintains the link between the unique code and the data subject in a keyfile, while in other projects, this connection is not necessary.
The manner in which pseudonymization is done varies between projects based on the research setup. It is good practice to describe the process of pseudonymization specific to your research either in your data management plan or a separate Pseudonymization Protocol. You can use the examples below to guide you in this process.
Warning: pseudonymization does not equal anonymization. An anonymized dataset does not allow for the re-identification of data subjects and is therefore no longer considered personal data. Even if all direct identifiers and your pseudonymization key have been replaced or removed, it might still be possible to re-identify some data subjects in your data because, in combination, certain attributes (e.g., combination of height, job occupation and location of data collection) may single out an individual.
Pseudonymization without a keyfile
This is the simplest form of pseudonymization, in which direct identifiers are either removed or replaced with a pseudonymization ID. It can be applied to direct identifiers in a single file or used to connect multiple files.
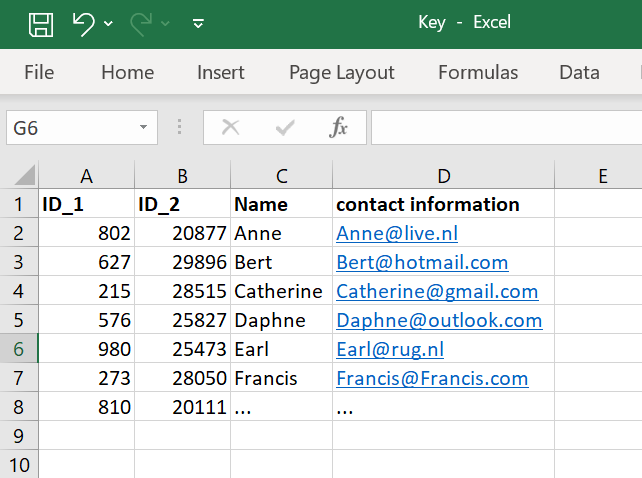
First, assign each data subject in your dataset a unique pseudonymization ID. That ID must be unique, non-informative, and non-derivable from personal data. In Excel, you can generate a randomized list of IDs by entering the following formula in the formula bar: =SORTBY(SEQUENCE(N), RANDARRAY(N)). Here, SEQUENCE(N) generates numbers from 1 to N, and RANDARRAY(N) randomizes their order. Choose an N larger than your sample size (e.g., for 100 data subjects, N = 1000). Remove all direct identifiers (e.g. names, email addresses, phone numbers) or replace them with these IDs. Use the same ID consistently across related files (e.g., transcripts, survey responses, and other data) to preserve linkability while protecting the identity of your data subjects (Figure 1).
Figure 1: Pseudonymization without a keyfile
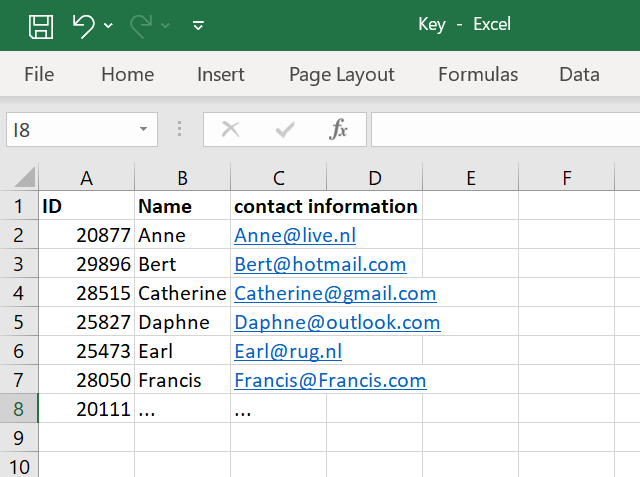
Pseudonymization with a keyfile
In this approach, you create pseudonymization IDs and securely store them together with contact details of your participants or other sensitive data in a keyfile. The dataset itself will only include the pseudonymization IDs, while the keyfile is kept apart and protected.
Creating a keyfile
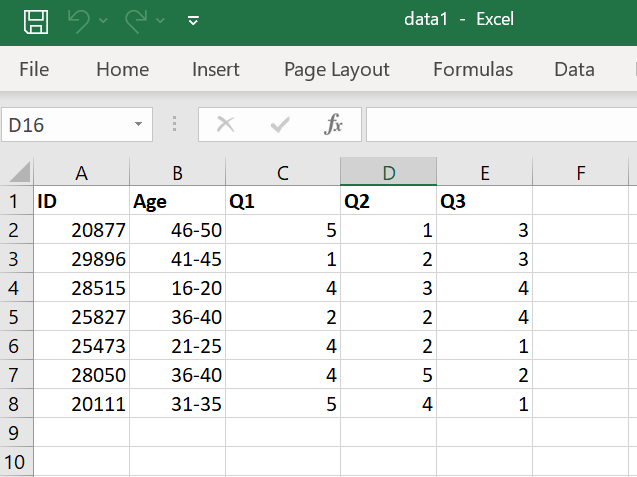
First, create a pseudonymization keyfile (e.g., in Excel or another UG-approved tool available in the University Workplace) that assigns each data subject a unique pseudonymization ID. For the creation of the pseudonymization IDs, you can follow the same steps as described in Pseudonymization without a keyfile. Direct identifiers such as names, email addresses, or phone numbers should be stored only in this keyfile (Figure 2) and removed from the research dataset. In the research dataset, remove all direct identifiers or replace them with the pseudonymization IDs.
Figure 2: Pseudonymization with keyfile
Managing the keyfile
You must store the keyfile securely in your X-Drive, Y-Drive or on Unishare in a separate location from the research data. Strictly limit access to the keyfile by using an extra layer of encryption (e.g. using Excel's encryption functionality or Veracrypt). This ensures that, even if the research dataset is shared or accessed by unauthorized parties, re-identification is only possible if the keyfile is also compromised. To avoid losing your encryption password, consider using a password manager like Bitwarden. Keep track of who is authorized to access the keyfile, and if necessary (e.g. longitudinal research), ensure that there are two people who have access to the key in case one becomes unavailable.
Only maintain a link between your research data and the individuals involved if necessary. Do not retain the keyfile longer than necessary for your research (e.g., exercising data subjects’ rights or informing data subjects about the research).
Double coding
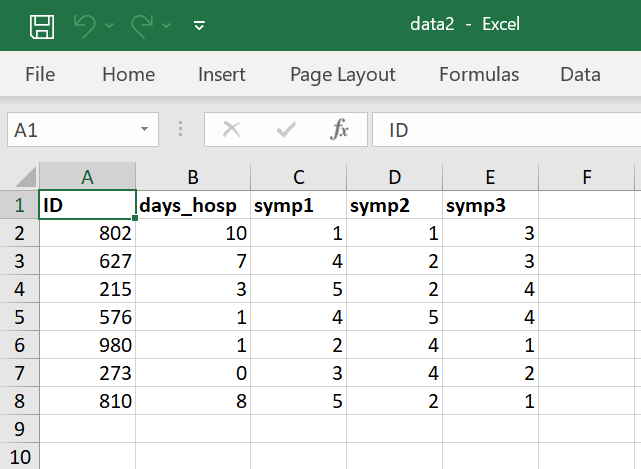
In some research projects, it may be necessary to obtain data about participants from external organizations (e.g., health information from medical files). When handling sensitive data, it is important to ensure that the external organization pseudonymizes the data with care before transfer. To enhance the privacy of your data subjects, it can be advisable to apply an additional layer of pseudonymization, also called double coding. This means that you replace the ID from the external organization with a new pseudonymization ID in your research dataset (Figure 3). As a result, the external organization cannot directly link the data to the IDs used in your study.
This approach reduces the risk of re-identification and protects sensitive information throughout the data transfer process. For guidance on implementing this protocol, contact your faculty data steward or the DCC.
Figure 3: Pseudonymization with double coding