Table of Contents
Exercises Advanced Hábrók Course
These exercises have been set up for the advanced course on using the Hábrók cluster. The course information can be found at: https://wiki.hpc.rug.nl/habrok/introduction/courses#advanced_habrok_course.
These exercises can be followed by anyone having a Hábrók account, as the required data is available to all users. They may be therefore useful if you are not able to follow the advanced course in person.
The accompanying course slides can be found on this wiki by clicking the link. More information on the cluster is also available on the wiki.
The hostname of the Hábrók cluster to use for the exercises is: login1.hb.hpc.rug.nl. Using one of the other login nodes will work as well.
End goal for the exercises
The end goal of the exercises is to be able to perform a filter operation on a set of images.
The exercises will start with studying how to improve a job submission script, that will be able to analyse a large set of images in an efficient way. For this, we will be using bash scripting.
The next set of exercises will focus on how a threaded OpenMP and a distributed MPI version of an image convolution program can be submitted and how the parallelisation of the program affects the performance.
Exercise 0
The files needed to complete these exercises are on GitLab. Get a copy of the exercise files by running:
git clone https://gitrepo.service.rug.nl/cit-hpc/habrok/cluster_course.git
in the directory of your choice.
Exercises - part 1
The code for the exercises can be found in the directory cluster_course/advanced_course, from where you performed the git clone. The structure of this folder is as follows:
advanced_course/ ├── 1.1_jobscript ├── 1.2_checkinput ├── 1.3_checksize ├── 1.4_folder ├── 1.5_loop ├── 1.6_jobarray ├── 2.1_singlecpu ├── 2.2_openmp ├── 2.3_mpi ├── 2.4_gpu └── images
Inspecting the folder for exercise 1.1, we see that it has the following structure:
1.1_jobscript/ ├── LICENSE.txt License file ├── Makefile Makefile ├── Microcrystals.jpg input image ├── Microcrystals.txt image URL ├── jobscript.sh job submission script └── mpi_omp_conv.c .c source file
with the appropriate explanations for what each file is.
For each of the exercises, you will have to build the executable, by loading the compilers, through
module load foss/2022b
and then using the command make to compile and link the executable. This has to be done within the subdirectory for each exercise. For example
cd 1.1_jobscript/ make
The output of make should look like:
mpicc -O2 -fopenmp -c mpi_omp_conv.c -o mpi_omp_conv.o mpicc -O2 -fopenmp mpi_omp_conv.o -o mpi_omp_conv
This runs the MPI enabled C compiler on the C source code, and links the resulting .o object file into an executable.
If you are interested, please have a look at the Makefile to see how the build process is arranged.
The end result will be a couple of new files, the object file mpi_omp_conv.o, and, most importantly, the executable mpi_omp_conv.
To run the program, the syntax of the command is:
./mpi_omp_conv source_image.rgb image_width image_height loops image_type
where:
source_image.rgb– the image we want to use, in anrgbfile formatimage_width– the width of the source imageimage_height– the height of the source imageloops– the number of passes through the imageimage_type– the type of the image, eitherrgborgrey
Most of the images on the Web are in formats other than rgb, but we can use a command line utility called convert, which is part of the ImageMagick software suite to convert between formats. Thus, before executing the mpi_omp_conv line above, we need to load ImageMagick and then convert source_image:
module load ImageMagick/7.1.0-53-GCCcore-12.2.0 convert source_image.jpg source_image.rgb
Once mpi_omp_conv has done its thing on the image, it will save the result as conv_source_image.rgb, and this has to be converted back to the JPEG format:
convert -size <image_width>x<image_height> -depth 8 conv_source_image.rgb conv_source_image.jpg
N.B: In the above line, do not include the angular braces < / >, they are there just for clarity.
Putting it all together, the commands that need to be run are:
# Clean up the module environment module purge # Load the compilers module load foss/2022a # Load the conversion tool module load ImageMagick/7.1.0-53-GCCcore-12.2.0 # Compile the program make # Convert the jpg file to the rgb format for easy processing convert source_image.jpg source_image.rgb # Run the convolution filter program on the image ./mpi_omp_conv source_image.rgb image_width image_height loops image_type # Convert the resulting file back to jpg format convert -size <image_width>x<image_height> -depth 8 conv_source_image.rgb conv_source_image.jpg # Remove the intermediate files rm source_image.rgb conv_source_image.rgb
Exercise 1.1: Parse command line arguments
In the directory 1.1_jobscript a sample jobscript has been prepared in the file jobscript.sh. The script looks as follows:
#!/bin/bash #SBATCH --nodes=1 #SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --mem=4GB #SBATCH --time=00:10:00 #SBATCH --partition=regular #SBATCH --job-name=Edge_detection # Clean up the module environment module purge # Load the compilers module load foss/2022b # Load the conversion tool module load ImageMagick/7.1.0-53-GCCcore-12.2.0 # Compile the program make # Convert the jpg file to the rgb format for easy processing convert Microcrystals.jpg Microcrystals.rgb # Run the convolution filter program on the image ./mpi_omp_conv Microcrystals.rgb 5184 3456 1 rgb # Convert the resulting file back to jpg format convert -size 5184x3456 -depth 8 conv_Microcrystals.rgb conv_Microcrystals.jpg # Remove the intermediate files rm Microcrystals.rgb conv_Microcrystals.rgb
An improvement for this script would be to take the name of the file to be processed from the command line arguments. So the improved script could be submitted as:
sbatch jobscript.sh Microcrystals.jpg
The filename when supplied as a command line argument will be available as the variable $1.
Improve the script so that this variable is used as the name of the file to be processed.
For the temporary files we can make use of filenames that will look like Microcrystals.jpg.rgb.
So the file to be processed will be $1, the result of the conversion will be $1.rgb, the result of the convolution program will be conv_$1.rgb, etc.
Also add a diagnostic message, telling us which file is being processed, using the echo command.
Check the script by running or submitting it, to see if it works.
You can study the resulting image using the command:
display -resize 30% conv_Microcrystals.jpg
Exercise 1.2: Validate input
The jobscript will now accept a filename for the file to be processed as a command line argument. The directory 1.2_checkinput contains an example jobscript, showing how this could have been done.
When we don't specify a filename, or specify a wrong filename, the script will result in weird errors. It would be nice if we would validate the input of the script. For this we will make use of the if and else statements. We will insert two checks into the script:
- Check if
$1is defined, to make sure that we have obtained input. For this we can make use of the-ztest:
if [ -z $VARIABLE ]
then
actions
fi
Check in the slides to see what the -z test does. The action can be an error message, explaining that you have to provide a filename as input.
- The second check will be to see if
$1is an existing file. For this we can make use of the-etest:
if [ -e $VARIABLE ]
then
actions
else
other actions
fi
This will be true if the $VARIABLE refers to an existing file. If true we can proceed with the normal operations of our script. If false we should print an error message and stop.
The indentation in above examples is to make the code more readable. You should get used to do this, as it is a common best practice. For languages like Python indentation is even an absolute requirement.
Insert these two tests into the job script. Both should print an error message and exit if the check fails. You can use the echo and exit commands for this, e.g.:
echo "This is an error" exit -1
The -1 is the return code of the script, non-zero values mean an error has occurred.
Check the script by running or submitting it, to see if it works.
Exercise 1.3: Use output from external program
Now move on to the directory 1.3_checksize. It contains an example of how exercise 1.2 could have been solved.
As you probably have seen, when studying the jobscript, the image size needs to be specified to the convolution program and the convert program. So for now our script only works for images with a predefined size.
In order to fix this we need to be able to extract the image size from an image file. The program identify, also a part of ImageMagick, can be used to to this.
Run the program identify on the image file. As you can see from the result the size of the image is returned by identify. In principle it is possible to extract the size from this output, using tools like grep, awk and sed, but this is too complicated for now. The image width can be extracted directly using the -format option for identify. To extract the width we can use:
identify -format "%w" imagefile
For the height we can use:
identify -format "%h" imagefile
Run these commands on the imagefile to see what they do.
As you have seen these commands result in numbers that we could use in our script. In order to store the output into a variable we can use the $( ) operator. E.g.:
myvar=$( command )
Generate variables width and height in the jobscript and apply them as parameters for the mpi_omp_conv program, instead of specifying the numbers.
For the second convert operation the size of the image is also specified. But since the numbers are separated by x we cannot simply make use of $width, but have to use {} to separate the x from the variable name.
Use $width and $height for the second convert operation. Check the script by running or submitting it, to see if it works.
Exercise 1.4: Work on image from different folder
In the next exercises, working from the directory 1.4_folder, we will perform operations on a number of images from a different folder/directory in the file system. This means that we have to be able to separate the path and filename. For instance:
../images/Cicada_III.jpg
should be separated in the path: ../images and the filename Cicada_III.jpg. For this we can make use of the tools dirname and basename. The first will return the directory, the second the filename.
Try the commands on the mentioned example file to see what they do.
We can now modify the jobscript by creating the filename and directory name. Modify the jobscript and store the filename in $filename and the directory name in $dirname.
Once we have these available in the jobscript we can use them. Replace the occurrences of $1 by $filename. Add the directory name through $dirname in the identify and first convert operations, so that you refer to $dirname/$filename.
By getting rid of $1 we make the code more readable for others.
Check the script by running or submitting it, to see if it works.
Exercise 1.5: Handle spaces in file names
We'll now continue with exercise 1.5 from the directory 1.5_spaces.
As you can see when listing the files in the image directory, some of the filenames have spaces in the filename.
When you run the script on such a file, it will not work, and we will get several error messages:
./jobscript.sh ../images/Sarus Crane Duet.jpg ERROR: File ../images/Sarus does not exist
And if we would fix the way we supply the file name, by adding quotes around the file name:
./jobscript.sh "../images/Sarus Crane Duet.jpg" ./jobscript.sh: line 11: [: too many arguments ./jobscript.sh: line 18: [: too many arguments ERROR: File ../images/Sarus Crane Duet.jpg does not exist
Note that the ERROR message is triggered by the error in the test at line 18, and is misleading.
To make the script more robust we will need to fix the way the argument is handled. This needs to be done by adding quotation marks around the argument. Like for example in line 11:
if [ -z "$1" ]
Note that you need to use the double quotes “, and not ', as the latter will cause the environment variable name to not be expanded but used directly. You can see this behaviour in for example:
echo '$USER' $USER
as opposed to
echo "$USER" myusername
Modify the script to fix all the occurrences of file names, both as $1, and as $filename, by adding quotation marks around the environment variable with the file name. Test the new script by submitting a job and supplying as argument an image with a space in its filename.
Exercise 1.6: Loop over number of images
If we need to process a lot of images, it would be nice if we could automate this process, instead of submitting all jobs by hand.
In this exercise (from the directory 1.6_loop), we will submit individual jobs through a loop. This will be done via a second script submit.sh. The starting version of this script looks as follows:
#!/bin/bash # Clean up the module environment module purge # Load the compilers module load foss/2022b # Compile the program make # Determine list of images images=../images/*.jpg # Submit a job sbatch ./jobscript.sh "../images/Sarus Crane Duet.jpg"
We've moved the compilation of the program to the submit script, as otherwise each job would try to compile the program, which may happen simultaneously, leading to errors.
Currently the script is not executable/runnable. Check the current properties of the file using: ls -l. Check if you can run it by issuing: ./submit.sh
To make it executable we have to modify the properties of the file. We can do this using:
chmod +x submit.sh
Perform this operation and see if we can run the script now. Check the properties again using ls -l.
The script now submits a job for a single image. Using a for loop we can submit a job for all the images we need to process. The for loop will look like:
for item in $list do actions done
where the actions part should contain the actual job submission, and $list should be our list of images.
Implement the for loop in the submit.sh script, and see if the script works. The result should be 31 processed images, and no error messages in the slurm output files.
Exercise 1.7: Use a job array
In this final exercise we are again going to process a lot of images, but this time we will make use of the scheduler's job array functionality. For a large number of tasks, this method is much more efficient than submitting a lot of individual jobs as we did in the previous exercise. The starting point for this exercise is in the directory 1.7_jobarray.
Since we are going to submit all work from a single job script, we need to make sure that the executable is in place, before we can run the script. This can be achieved by running the following commands:
module load foss/2022b make
First we need a list of all images to be processed, and this time we are going to store this list in a text file instead of in a variable.
Run a command (you can use ls for this) that lists all images in ../images, and redirect (using >) the output to a file, e.g. images.txt. Make sure that each image gets printed on a separate line, check this by inspecting the file with cat or less.
Now open the script jobscript.sh. Instead of passing the filename of an image, we are going to pass the filename of the file that you just created and that contains the filenames of all images to be processed as an argument to our jobscript.
The job array functionality is going to run this job N times, once for each image; for the n-th job we need to find the n-th image by taking the n-th line from our file. We have to do this at the top of the second if statement:
# Check if file exists
if [ -e $1 ]
then
# Find the n-th image in the input file
image=$( )
echo "Processing image: " $image
Insert the right command between the parentheses: it needs to print (use cat) the file and take the n-th line, where n is $SLURM_ARRAY_TASK_ID, using the head and tail commands. See the example in the slides to find out how you can get the n-th line of a file.
Finally, to make this a job array, we have to set a range that defines how many times this job is going to be run. Since we use $SLURM_ARRAY_TASK_ID to refer to a line number, we want the range to go from 1 to N, where N is the number of images. But since we are still testing our script, let's start with a smaller range:
Add a line to the header of the script that defines a range from 1 to 3 using –array=1-3. Then submit the job and check what happens by inspecting the output files. Verify that indeed the first three images of your input file have been processed.
Once you are sure that everything went fine, we are now ready to submit all tasks.
Count the number of items in your input file (you can use: wc -l <filename>) and modify the range in your jobscript: make sure it will process all the images. Submit the job, and check that all images have been processed, i.e. that you have the same number of output files as input files.
As a final remark: each of these N jobs now ran on a single core. Of course you can also run the MPI version of the application in a job array, and request more than one core or node for each task.
Exercises - part 2
For this second part of the Exercises, we will return to the jobscript we prepared for exercise 1.1, which has all parameters (image file name, image size, etc.) hardcoded in the jobscript.sh file. The command part of this jobscript will stay mainly unchanged, while we will focus on modifying the requirements part, which specifies the resources we request from SLURM for the job.
Exercise 2.1: Single CPU
Modify the jobscript.sh file from the folder 2.1_single_cpu/ to run a job on a single core. We have set placeholders instead of actual numbers for certain SLURM parameters. Modify these accordingly. Submit the job and check that the resulting output image (conv_Microcrystals.jpg) has been processed.
Check the output of the job for the following:
- No. of cores used
- CPU efficiency
- Running time
You can study the resulting image using the command:
module load ImageMagick/7.1.0-53-GCCcore-12.2.0 display -resize 30% conv_Microcrystals.jpg
Exercise 2.2: OpenMP
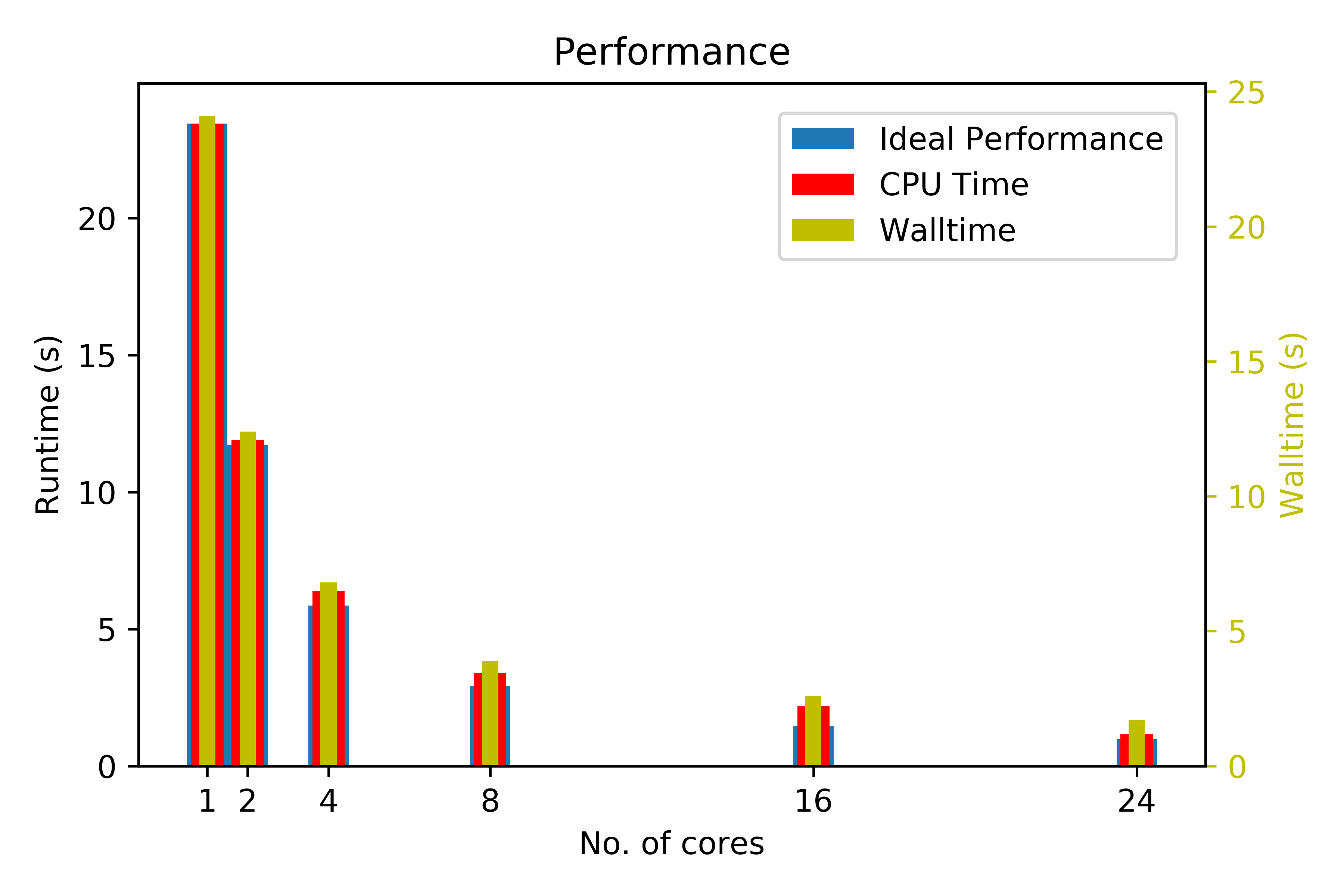
This exercise will have you run our image blurring app on multiple CPUs on a single node. Go to folder 2.2_openmp/ and modify the jobscript.sh file to use 2, 4, 8, and 16 CPUs on a single node.
For each, make a note of the runtime and wallclock time. How does the runtime scale with the number of CPUs? What about the wallclock time?
Advanced explanation of the OpenMP implementation. You can skip to the next exercise if you like. If you are curious about the implementation you can look at the source code mpi_omp_conv.c. The OpenMP programming is done using directives that start with #pragma omp. There are several of them:
#pragma omp parallel
num_threads_per_task = omp_get_num_threads();
This section will be run in the OpenMP case and will request the number of threads that have been started, which is used in the diagnostics.
The next pragma is appearing twice, once for grayscale images, and once for RGB images.
#pragma omp parallel for shared(src, dst) schedule(static) collapse(2)
for (i = row_from ; i <= row_to ; i++)
for (j = col_from ; j <= col_to ; j++)
convolute_rgb(src, dst, i, j*3, width*3+6, height, h);
This section will take both for loops and distribute the i and j (both because of the collapse(2)) values over the available threads. The arrays src and dst are shared. This means that only a single thread can update a particular i,j combination in the arrays src and dst. If not the outcome will be dependent on the order of execution by these threads.
As you can see parallelising with OpenMP can be done without making many changes in the original program, which is a big advantage.
Exercise 2.3: MPI
Let's have a look at an MPI job. Folder 2.3_mpi contains the jobscript.sh file that you need to modify. Looking at this file you will have noticed something new: the command that runs the blurring algorithm has now changed from
./mpi_omp_conv source_image.rgb image_width image_height loops image_type
to
srun ./mpi_omp_conv source_image.rgb image_width image_height loops image_type
This is because we are now using MPI, and the srun command is needed to run an MPI program. This is because the program is now a collection of processes, communicating through MPI. Each process needs to be started individually on the nodes the calculation will be running on, while being aware of the overall MPI context.
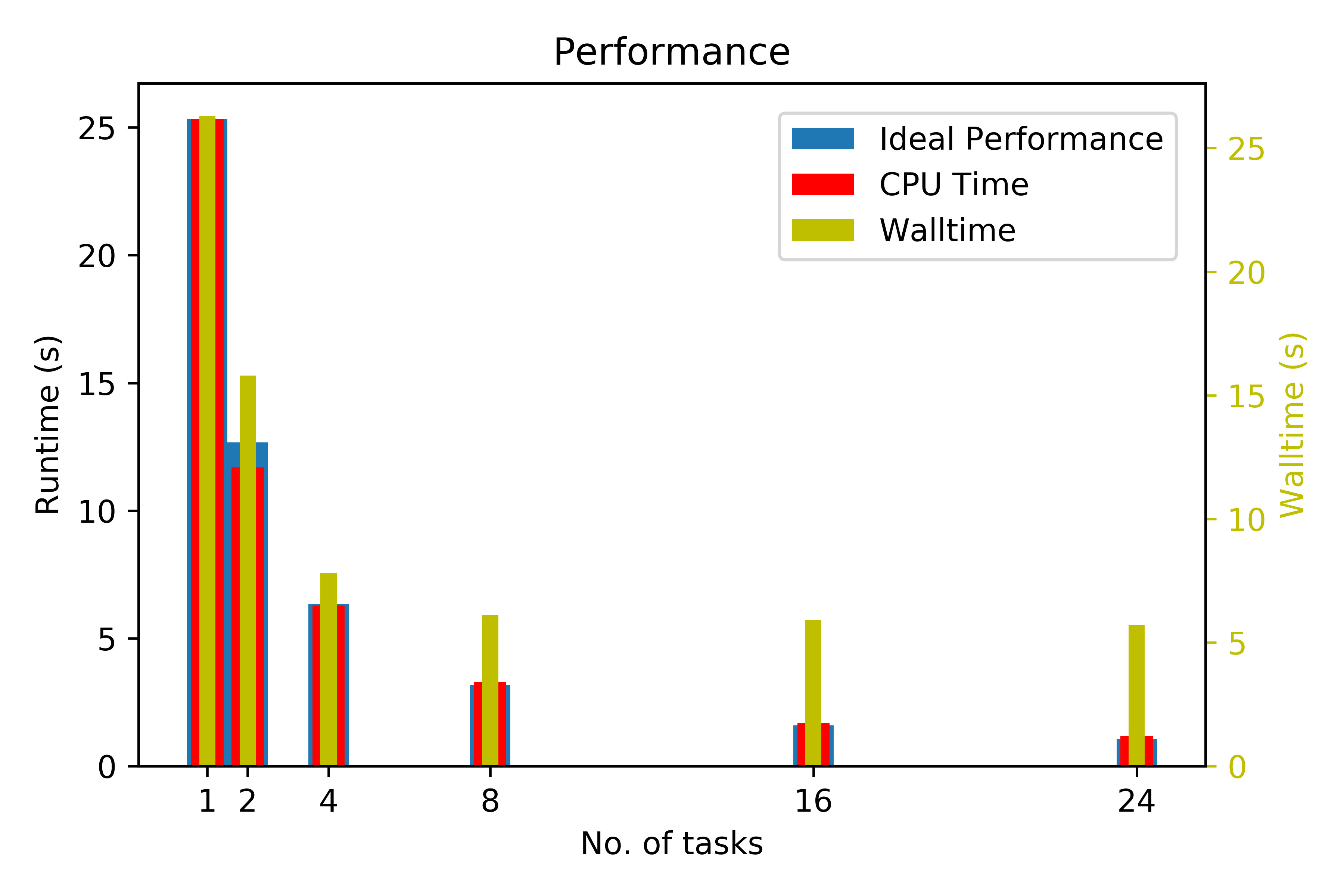
Run the blurring app with 2, 4, 8, and 16 MPI tasks, each using one core and running on a separate node. Make note of the runtimes, as well as the overall wallclock time. How does this differ from the previous exercise?
You can try to resubmit the job with 4 nodes to a parallel partition in which the nodes have a faster low-latency interconnect. Does this make a difference? Note that using more nodes will result in a long waiting time as there are only 24 nodes in this partition.
The “low-latency” means that the time it takes for the first byte of a message to reach the other node is very small. It only takes 1.2 μs on our 100 Gb/s Omni-Path network, whereas on our 25 Gb/s ethernet the latency is 19.7 μs.
Advanced explanation on MPI. You can skip to the next exercise if you like. The MPI implementation is done by inserting specific MPI function calls into the program. MPI programs consist of a collection of indepent processes, that use explicit communication statements to exchange information.
For a lot of programs this can be done with limited changes. Especially when a lot of the data is made available to all participating processes. In that case the processes can work independently and only exchange critical data.
In our case each process is setup to only load and process a part of the image. This means that also the data loading is done with MPI. Furthermore each process processes a part of the image. This means that all data that will be required by another process for the next step needs to be transferred explicitly to that process.
When you look at the code you will see a lot of MPI function calls. The main part consists of communication to neighbouring processes, for which these have been laid out in a grid. Each process will then have neighbours north, east, west and south, with which to communicate.
As you can see from the source code this is quite complex.
The main advantage of MPI is the possibility to run it on multiple computers, allowing for a much larger scale of parallelisation.
Exercise 2.4 GPUs
So far, you've been using either multiple CPUs on a single machine (OpenMP), or on multiple machines (MPI), to parallelize and speed up the image processing. In this exercise, you will have a look at how to use GPUs to achieve parallelization. In the folder named 2.4_gpu/ you will find a simple jobscript which you need to modify.
We've reserved one GPU node with 2 V100 GPUs for this course. The reservation is called advanced_course. Make use of it by adding the following line to your script:
#SBATCH --reservation=advanced_course
Request 1 (one) GPU of type V100 on the gpu partition. You can find out how to do this on this wiki and in the slides.
Compare the times from exercise 2.2 with what you obtain now. You might want to make the problem a bit harder by processing all the files from the images folder.
Programming the GPU is not for the faint of heart, though OpenACC makes it relatively easy. If you read C code, study the code and try to figure out where is the GPU used. If you plan to use an existing application with the GPU, you needn't worry about the implementation.
Advanced explanation of the OpenACC implementation for the curious If you are interested in how the GPU implementation has been done, you should take a look at the #pragma acc directives in the code.
The main loop is parallelized in a similar way as was done for the OpenMP case:
#pragma acc loop gang, vector independent collapse(2)
for (i = row_from ; i <= row_to ; i++)
for (j = col_from ; j <= col_to ; j++)
convolute_rgb(src, dst, i, j*3, width*3+6, height, h);
This tells the compiler to run this loop in parallel on the GPU. Again the two loops are collapsed to increase the number of tasks to be parallelized. The keywords gang and vector tell the GPU how work should be distributed over its resources. This is related to the fact that a GPU contains a number of processing units which each can process many threads.
The main challenge in GPU code is minimizing data transfers between the memory of the computer (host) and the memory on the GPU card, as this transfer is time-consuming. A simplified implementation might have used managed memory (where the compiler takes care of this), but this is less portable.
The data management is done using OpenACC data pragmas. The code contains the following pragmas:
#pragma acc enter data copyin(h[0:3][0:3])
and
#pragma acc enter data copyin(src[0:array_size]), create(dst[0:array_size])
These copyin directives tell the compiler that data needs to be transferred from the host to the GPU at this point. The create causes memory to be made available for the temporary dst array, which is used to store intermediate data.
The opposite directive for copyin is copyout, where data is copied from GPU back to host.
#pragma acc exit data copyout(src[0:array_size])
In the main convolute routine, we have to tell the compiler that the data on the GPU is already present. This is the main trick to make sure no unnecessary copying of data is done. And, to be able to use this, we had to make sure that the data is already on the GPU using the previous copyin statement.
#pragma acc data present(src), present(dst), present(h)
The last OpenACC statement that we need is the cleanup of our data structures.
#pragma acc exit data delete(src[0:array_size],dst[array_size],h[0:3][0:3])