Table of Contents
De-identification, anonymization and pseudonymization
Introduction
De-identification is the masking, manipulation or removal of personal data with the aim of making individuals in a dataset less easy to identify. It is especially important when you want to share, publish or archive your dataset, but it can also help protect your participants' privacy in case of a data leak during your research. During the different phases of your research, you should determine whether it is possible to de-identify your dataset while also keeping in mind its usability.
Anonymization versus pseudonymization
Pseudonymization
Pseudonymization is a de-identification procedure which is often implemented during data collection. During pseudonymization personally identifiable information is replaced by a unique alias or code (pseudonym). In general, the names and/or contact details of data subjects are stored with this pseudonym in a so-called keyfile. The keyfile enables the re-identification of individuals in the dataset. Keyfiles are stored separately from the rest of the data, and access should be restricted. In contrast to an anonymized dataset, a pseudonymized dataset, in principle, still allows for the re-identification of data subjects.
→ Refer to our page on pseudonymization for practical advise on its implementation.
Anonymization
Anonymization is a de-identification procedure during which “personal data is altered in such a way that a data subject can no longer be identified directly or indirectly, either by the data controller alone or in collaboration with any other party.“ (ISO 25237:2017 Health informatics -- Pseudonymization. ISO. 2017. p. 7.). In contrast to a pseudonymized dataset, an anonymized dataset does not allow for the re-identification of data subjects and is therefore no longer considered personal data.
Warning: de-identification does not equal anonymization. Even if all direct identifiers and your pseudonymization key have been replaced or removed, it might still be possible to re-identify some data subjects in your data because, in combination, certain attributes (e.g., combination of height, job occupation and location of data collection) may single out an individual.
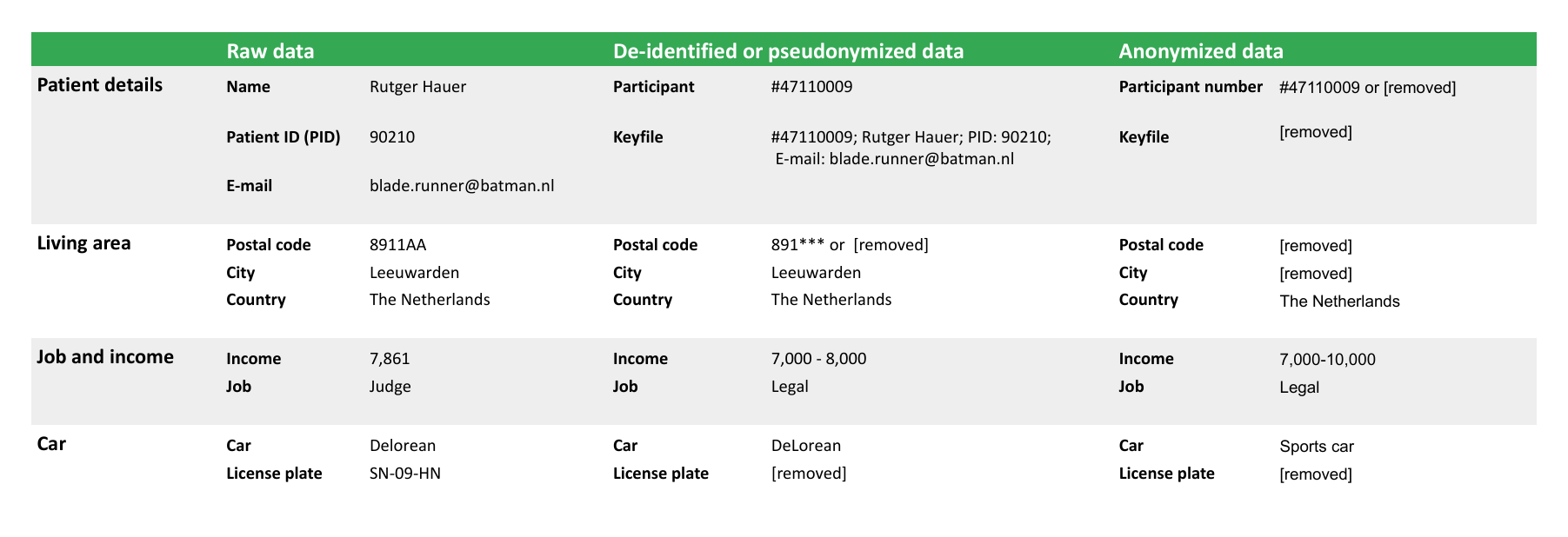
Table 1: De-identification matrix adapted from LCRDM (2019). This matrix is an example of what de-identification and anonymization could look like in research. The identifiability of your data largely depends on the context of your research and only partly on the variables you collected. For example, the variable judge could be more identifiable for a person living in Leeuwarden than for a person living in Amsterdam, because more judges live in Amsterdam.
General de-identification techniques
Use the de-identification techniques outlined below to reduce the identifiability of your dataset. Be aware that these techniques often affect its analytical value. Therefore, always make sure to document the way you transformed your data.
You can apply these techniques during different phases of your research:
- After data collection, to protect participants when analyzing their data
- Before sharing data with collaborators or other third parties
- Before archiving data
- Before publishing data (with access restrictions)
Removing or suppressing
When personal data is not particularly relevant for your research or is highly sensitive, you can consider removing or suppressing these elements.
- Remove variables that reveal rare personal attributes.
- Remove direct identifiers, such as names or Patient ID.
- Use restricted access to your data and only provide those variables to researchers that are necessary to answer their research question.
Replacing or masking
A practice in which you replace sensitive personal data with values or codes that are not sensitive:
- Replace direct identifiers (‘name’) with a pseudonym (‘X’).
- Make numerical values less precise.
- Replace identifiable text with ‘[redacted]’.
Masking is typically partial, i.e. applied only to some characters in the attribute. For example, in the case of a postal code: change 9746DC into 97∗∗∗∗.
Aggregation & generalization
Reduce the level of detail of your dataset by generalizing variables, which makes it harder to identify individual subjects. This can be applied to both quantitative and qualitative datasets. For example, changing addresses into neighbourhood or city, and changing birth date or age into an age group.
Bottom- and top-coding
Bottom- and top-coding can be applied to datasets with unique extreme values. Set a maximum or minimum and recode all higher or lower values to that minimum or maximum. Replace values above or below a certain threshold with the same standard value. For instance, top-code the variable ‘income’ by setting all incomes over €100.000 to €100.000. This distorts the distribution, yet leaves a large part of the data intact.
Adding noise
Noise addition is usually combined with other anonymization techniques and is mostly (but not always) applied to quantitative datasets:
- Add half a standard deviation to a variable.
- Multiply a variable by a random number.
- Blur photos and videos or alter voices in audio recordings (see below).
Permutation
Permutation is applied to quantitative datasets. Shuffle the attributes in a table to link some of them artificially to different data subjects. The exact distribution per attribute of the dataset is hereby retained, but identification of data subjects is made more difficult.
Synthetic data
Synthetic data are artificially generated rather than collected from real-world events (e.g., flight simulators or audio synthesizers). In research, synthetic datasets can be designed to replicate the statistical patterns of real datasets that are too sensitive to share openly. Creating a synthetic version of your dataset allows researchers to:
- Access relevant data without compromising the privacy or safety of data subjects.
- Evaluate whether the dataset suits their research needs and begin developing code, refining models, and testing hypotheses.
- Educate students on how to preprocess and analyze sensitive data without exposing information about real individuals.
Two examples of synthetic data publications:
- De-identification when making datasets FAIR: Two worked examples from the behavioral and social sciences. (van Ravenzwaaij et al., 2025)
Watch this video for an accessible introduction to synthetic data
For more in-depth information on these techniques, including guarantees, common mistakes, and potential failures, please refer to (Chapter 3 of) the Opinion 05/2014 on Anonymization Techniques (Working Party Article 29 of Directive 95/46/EC, 2014)
Research specific de-identification techniques
Videos or images
Researchers use videos or images to record real-world behaviour, interactions, or experiments in detail, for example, tracking how people move, communicate, or perform tasks over time. It is important to de-identify this type of data, because they can easily reveal faces, voices, or surroundings, and leaving those visible can reveal participants’ identities.
(Click) Metadata de-identification

Audio data
Audio recordings are typically collected to capture exactly what participants say during interviews or focus groups, or to study voice patterns. Audio data itself can contain identifying information: Participants may be recognizable from their voice by other people, and modern speech recognition technologies can also be used to identify participants. For this reason, audio data should be de-identified before further use or sharing.
(Click) Acoustic de-identification
(Click) Metadata de-identification